Gitlab Repo mdi-gitlab
I've hosted my code for this project at https://gitlab.com/dibz15/cs825_project. This page was produced from the tictactoe.ipynb notebook file.
Introduction
Upon starting this project, my primary goal was to become familiar with the most important areas of multi-agent reinforcement learning (MARL) in order to have a broad understanding of the field. After that, I wanted to implement some modern algorithm(s) with which I could showcase recent/state-of-the-art methods in MARL for playing simple multiplayer games. Unfortunately, I vastly underestimated both the amount of literature available on this topic and also the difficulty that I would have in setting up even a "basic example". But I will detail that further on. First, I briefly discuss the literature review that I performed for the project.
General Reinforcement Learning
To start this journey, I sought to become more familiar with reinforcement learning in general, and I hoped to connect it back to the concepts that have been covered in CS825: Game Theory and Multi-Agent Systems. The most obvious way to survey the field of RL and its many components is Reinforcement Learning by Sutton and Barto (2018).
I spent a significant amount of time reading sections I (Tabular Solution Methods) and II (Approximate Solution Methods), and I learned a considerable amount in the process. I have always struggled with reading advanced mathematics notations, so I appreciate that this text accompanies its notation with in-depth descriptions of the equations and the algorithms that they represent. With that said, I would have had a much easier time understanding it if I had discovered that there's a "Summary of Notation" at the beginning of the book before I finished reading it. Oh well.
Overall, my biggest takeaways from the book were that 1) RL is a much more extensive field of study than I previously understood, 2) approximate solution methods are probably where the future of RL will keep heading, and 3) policy gradient methods are really interesting.
However, one area of RL that is not covered in the text is MARL. So, I continued my research.
Multi-Agent Reinforcement Learning
To get a general survey of MARL and its available methods, I found it really helpful to read "An Overview of Multi-Agent Reinforcement Learning from Game Theoretical Perspective" by Yang and Wang (2020). In fact, what I really appreciate about the text is that it begins with an overview of single-player RL using both value-based and policy-based methods, and then maps those concepts to MARL and stochastic games as a multi-player extension to Markov Decision Processes (MDPs). This can be summarised by this section of their text:
"In the multi-agent scenario, much like in the single-agent scenario, each agent is still trying to solve the sequential decision-making problem through a trial-and-error procedure. The difference is that the evolution of the environmental state and the reward function that each agent receives is now determined by all agents’ joint actions... In other words, each agent aims to find a behavioural policy (or, a mixed strategy in game theory terminology (Osborne and Rubinstein, 1994)), that is, that can guide the agent to take sequential actions such that the discounted cumulative reward in Eq. (12) is maximised" (pp. 15-17).
As a practical takeaway for the application side of this project, I found it interesting that the process for Q-learning for single and multi-agent scenarios is nearly identical. Specifically, each agent maintains its own Q-table (though this can differ in some implementations to be a single Q-table for all agents), and updates with consideration to the interests of all other players.
Policy-based methods are adjusted similarly, in that each agent maintains its own set of policy parameters (e.g. a neural network).
MARL Rabbit Hole
After that brief introduction into the theoretical concepts behind MARL methods, I wanted to find some recent methods that I could apply to actually getting an agent to learn to play a multiplayer game. Because of this, I was very excited to learn about ideas such as Proximal Policy Optimisation for MARL (Yu et al., 2022), Deep Counterfactual Regret Minimisation (Steinberger, 2019), Imitation Learning (Inverse RL) (Ciosek, 2022), and a bunch of other really amazing reinforcement learning techniques/examples for MARL:
- DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning (Zha et al., 2021)
- Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model (Schrittwieser et al., 2020)
- Player of Games (Schmid et al., 2021)
Not to mention, there is a large collection of great resources for implementing RL in real applications:
- Gymnasium: https://gymnasium.farama.org/
- PettingZoo (basically Gymnasium for MARL): https://pettingzoo.farama.org/
- RLCard: https://rlcard.org/
- RLlib: https://docs.ray.io/en/latest/rllib/index.html
- MARLlib: https://github.com/Replicable-MARL/MARLlib
Among many others. Needless to say, even after taking a glance at what may be considered to be fairly trivial examples, I became quite overwhelmed by the task of implementing MARL for even a simple game for this project. Because of this, I decided that the best thing that I could do to produce anything remotely interesting would be start with the basics.
"The Basics"
In the beginning, there was tic-tac-toe. And Sutton and Barton assured us that it is not trivial to solve.
But, in the spirit of game theory, I wanted to attempt to build an agent to play an incomplete information game such as Liar's Dice (also known as Dudo). It turns out that someone else (Thomas Ahle) had the same idea about a year ago and already wrote a really interesting blog about it. In fact, you can play against their agent online at dudo.ai. It's really impressive!
While I considered attempting to replicate his results, this turned out to be fairly complicated. It's part of the reason my "rabbit hole" from earlier included counterfactual regret minimisation. So, I moved on and settled on one of the cornerstones of RL: Q-learning. And, since PettingZoo already includes a tic-tac-toe environment, that was my game of choice.
Q-Learning
I appreciate the equation used by Yang and Wang to break down the components of the Q-learning algorithm, so I'm pasting it here for reference:
The main idea is iterative updating of state-action pairs. Or, for each state, what is the expected value of a specific action? This is known as a value-based method. Two tunable parameters for the algorithm are and , where represents the 'learning rate' (or how quickly do we update our value function based on new information) and represents the 'discount factor' (or how important we consider the value of future states compared to the current state).
Tic-tac-toe
Rather soon after playing tic-tac-toe a number of times, it becomes apparent to a human that tic-tac-toe is actually a fairly boring game. With a few mental heuristics, we learn quickly how to avoid losing to our opponent. This rather quickly leads to the inevitable: perfect play in this game always leads to a draw.
But intuition isn't yet easy to build into a machine, so it must play by either an exhaustive search (consider every possible combination of next states in a tree search) or an iterative learning approach. From what I have read online, it seems like the classic algorithm for solving tic-tac-toe is to use minimax trees. However, I thought that it would be personally more interesting to use a technique that doesn't assume anything about the game environment. As we are discussing RL, then I have selected to 'teach' an agent to play tic-tac-toe with the Q-learning algorithm.
Self-Play
Giovanni and Zell (2021) give a really succinct but informative review of self-play that is worth reading. I think that it's interesting that self-play is where MARL significantly overlaps with concepts from game theory. I don't engage with it very much here, but it's a very interesting area of research that I think is significant because it allows agents to learn by themselves.
Multi-Agent Q-Learning for Tic-tac-toe
As mentioned earlier, Q-learning for multiple agents is a fairly simple extension of Q-learning for a single agent. The catch is that the value (Q) function for each agent is maintained separately. However, depending on the system, this doesn't always have to be true. In the tic-tac-toe environment provided by the PettingZoo library, the observable action space is set up specifically to allow for agent self-play (for a brief overview of the types of opponents that can be modelled in Multi-agent Q-learning, see this post). The way that this is achieved is that the representation of the environment is swapped for each player. This allows for the Q-learning agent to learn from the perspective of both players at the same time, using the same Q-table.
Tic-tac-toe Q-Agent
All my Tic-tac-toe Q-learning code for training is available in my tictactoeqlearn.py script for this project, but I will explain the key parts in this notebook.
To start, I've adapted the example Q-Agent code from the Gymnasium library's Blackjack example:
from __future__ import annotations
from collections import defaultdict
import pickle
import matplotlib.pyplot as plt
import numpy as np
# import seaborn as sns
# from matplotlib.patches import Patch
from tqdm import tqdm
from pettingzoo.classic import tictactoe_v3
import numpy as np
from torch.utils.tensorboard import SummaryWriter
import os
from datetime import datetime
# I used this function to transform the 'two plane' structure of the observation space
# defined by the Tic-tac-toe PettingZoo environment into a friendlier single plane space
# where the current player is 1 and the other player is -1. This make it easier to visualise
# the space and debug the learning process.
def transformObservation(observation_arr, neg_pos:int = 1):
assert neg_pos in [0, 1]
return (-1 + 2*neg_pos) * observation_arr[:, :, 0].T + (1 - 2*neg_pos) * observation_arr[:, :, 1].T
class TicTacToeAgent:
def createZeros(self):
return np.zeros(self.env.action_space(self.env.agents[0]).n)
def __init__(
self,
env,
learning_rate: float = 0.01,
initial_epsilon: float = 0.99,
epsilon_decay: float = 0.001,
final_epsilon: float = 0.1,
discount_factor: float = 0.95,
):
"""Initialize a Reinforcement Learning agent with an empty dictionary
of state-action values (q_values), a learning rate and an epsilon.
Args:
learning_rate: The learning rate
initial_epsilon: The initial epsilon value
epsilon_decay: The decay for epsilon
final_epsilon: The final epsilon value
discount_factor: The discount factor for computing the Q-value
"""
self.q_values = defaultdict(self.createZeros)
self.env = env
self.lr = learning_rate
self.discount_factor = discount_factor
self.epsilon = initial_epsilon
self.epsilon_decay = epsilon_decay
self.final_epsilon = final_epsilon
self.training_error = []
def get_action(self, obs) -> int:
"""
Returns the best action with probability (1 - epsilon)
otherwise a random action with probability epsilon to ensure exploration.
"""
# with probability epsilon return a random action to explore the environment
valid_actions = np.asarray((obs['action_mask'] == 1).nonzero())[0]
if np.random.random() < self.epsilon:
if len(valid_actions) == 0: print(obs)
action = np.random.choice(valid_actions)
return action
# with probability (1 - epsilon) act greedily (exploit)
else:
obs_str = str(transformObservation(obs['observation']))
actions = self.q_values[obs_str]
if np.count_nonzero(actions) == 0:
choice = np.random.choice(valid_actions)
else:
choice = int(np.argmax(actions))
return choice
def update(
self,
obs,
action: int,
reward: float,
terminated: bool,
next_obs,
):
obs_str = str(transformObservation(obs['observation']))
next_obs_str = str(transformObservation(next_obs['observation']))
"""Updates the Q-value of an action."""
future_q_value = (not terminated) * np.max(self.q_values[next_obs_str])
temporal_difference = (
reward + self.discount_factor * future_q_value - self.q_values[obs_str][action]
)
self.q_values[obs_str][action] = (
self.q_values[obs_str][action] + self.lr * temporal_difference
)
self.training_error.append(temporal_difference)
def decay_epsilon(self):
self.epsilon = max(self.final_epsilon, self.epsilon - self.epsilon_decay)
def load_from_file(self, pkl):
with open(pkl, 'rb') as f:
self.q_values = pickle.load(f)
self.epsilon = 0
self.final_epsilon = 0.0
self.epsilon_decay = 0.0
return self
In the above class, we can see how the Q-learning equation from before maps almost directly to the code on lines 74-81, where we are updating our value function with the new value for the state-action pair. This is balanced by the set learning rate and discount factor values.
In the get_action function, we used a stored epsilon value to encourage random exploration in our learning algorithm. If the agent isn't acting randomly (and a choice exists with a non-zero expected value) then the maximum value action is selected.
Training
The training loop for the agent consists of playing thousands of complete games through self-play. Initially, the agent moves entirely randomly. However, as the Q-table is updated and has values associated with certain actions then the agent's win-rate slowly converges as it improves. Optimally, the agent should converge to a point where it always either wins or draws the game.
The loop for a single 'game' is quite simple. It consists of the current agent/player observing the current state of the game, and then taking an action based on the observed state. Whether or not tha action is random, after the action is taken then the updated state of the game is again observed. The reward, if there is any, is used to update the agent's Q-table using information about the two observed state-action pairs. This continues until the game is ended.
Here's the code for the game loop:
def play_episode(env, agent : TicTacToeAgent) -> dict:
done = False
rewards = { agent: 0 for agent in env.agents }
last_action = { agent: 0 for agent in env.agents }
last_observation = { agent: None for agent in env.agents}
# play one episode
while not done:
# Get active agent (current player)
curr_agent = env.agent_selection
# Observe the state from this agent's perspective
observation = env.observe(curr_agent)
# Q-agent makes an action determination
action = agent.get_action(observation)
# Store last observation and action (useful for when the game has ended)
last_observation[curr_agent] = observation
last_action[curr_agent] = action
env.step(action) # Advance game state with agen't choice
# Check reward and if the agent is terminated (if game has ended)
curr_agent_terminated = env.terminations[curr_agent]
first_action_reward = env.rewards[curr_agent]
# Update our q-values with the state change, action, and action reward
agent.update(observation, action, first_action_reward, False, env.observe(curr_agent))
if curr_agent_terminated:
# Game is over
done = True
other_agent = env.agent_selection
# Assign rewards for each agent (+1 for winner, -1 for loser. Illegal moves mean the agent gets -1 immediately)
rewards = { agent: env.rewards[agent] for agent in env.agents }
# If a new player is selected when the game ends, update the q-values with the perspective of that player
if other_agent != curr_agent:
agent.update(last_observation[other_agent], last_action[other_agent], env.rewards[other_agent], False, env.observe(other_agent))
return rewards
Note that after the game is ended I take extra care to update the Q-table one last time to ensure that it learns from the last move of the game after it has ended. I noticed that adding this increased the overall model performance.
The full training loop is given below. Note how one game (episode) is played through, as explained above. Then, the performance is logged. I've also added a feature where the trained agent plays against a random player, as a sort of validation.
play_expert = (not not args.expert)
for episode in tqdm(range(n_episodes)):
if not play_expert:
rewards = play_episode(env, agent)
else:
rewards = play_episode_with_expert(env, agent, expert_agent)
if args.expert and episode % (n_episodes // 10) == 0:
play_expert = (not play_expert)
env.reset()
agent.decay_epsilon()
ma1.update(rewards[env.agents[0]])
ma2.update(rewards[env.agents[1]])
writer.add_scalar('train/avg_reward_p1', ma1.average(), episode)
writer.add_scalar('train/avg_reward_p2', ma2.average(), episode)
writer.add_scalar('train/num_q_values', len(agent.q_values), episode)
writer.add_scalar('train/epsilon', agent.epsilon, episode)
if episode % test_every == 0:
randAgent = TicTacToeAgent(env, initial_epsilon=1.0, final_epsilon=1.0)
randAgent.epsilon = 1.0
old_epsilon = agent.epsilon
agent.epsilon = 0
p1Res, p2Res = play_test_game(agent, randAgent, env, test_length)
writer.add_scalar('train/win_rate', p1Res[0]/test_length, episode)
writer.add_scalar('train/draw_rate', p1Res[2]/test_length, episode)
writer.add_scalar('train/lose_rate', p1Res[1]/test_length, episode)
agent.epsilon = old_epsilon
env.reset()
The key hyperparameters and my settings for them are listed below. Note that the epsilon value decreases as training commences. The idea behind that is that as the agent explores and learns about more states, then it should perform better when allowed to choose. This is the concept of exploration vs. exploitation.
I want to point out that my learning rate and discount factor are much higher than I originally thought I would need. Since I'm used to ML/DL, I originally started with an LR of 0.01. However, training at that rate was way too slow. I believe that one big reason for this is that the reward in tic-tac-toe is only given at the end of a game. That is, if the agent loses then the Q-table is updated with a reward value of -1, and if it wins then it is +1. This is how the tic-tac-toe environment in PettingZoo is set up. This is also why I have the discount factor set quite high as well. Because, overall, there is a fairly large gap between an action (say the first move of a game) and the reward (winning or losing, several states later). In order to propagate the reward information back to the earlier states of the game, it is necessary to have these values higher so that the future reward is considered more important for earlier game states.
learning_rate = 0.5
n_episodes = 200000
start_epsilon = 1.0
epsilon_decay = start_epsilon / (n_episodes / 2) # reduce the exploration over time
final_epsilon = 0.1
discount_factor = 0.95
Training can be performed using my training script by calling:
python tictactoeqlearn.py --file qtable.pkl
Where qtable.pkl is the Pickle file that will store the final Q-table values for later inference.
Results
Random Training
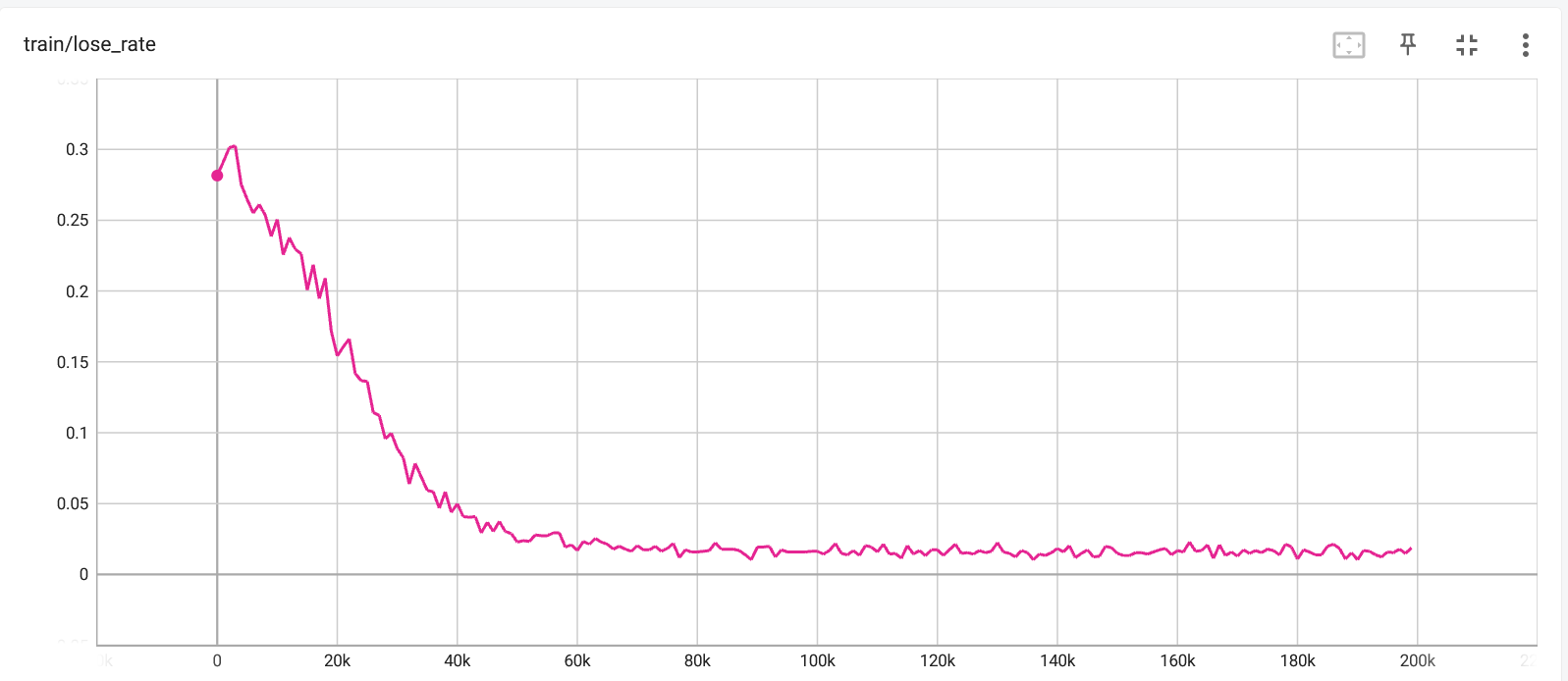
Loss rate per iteration. |
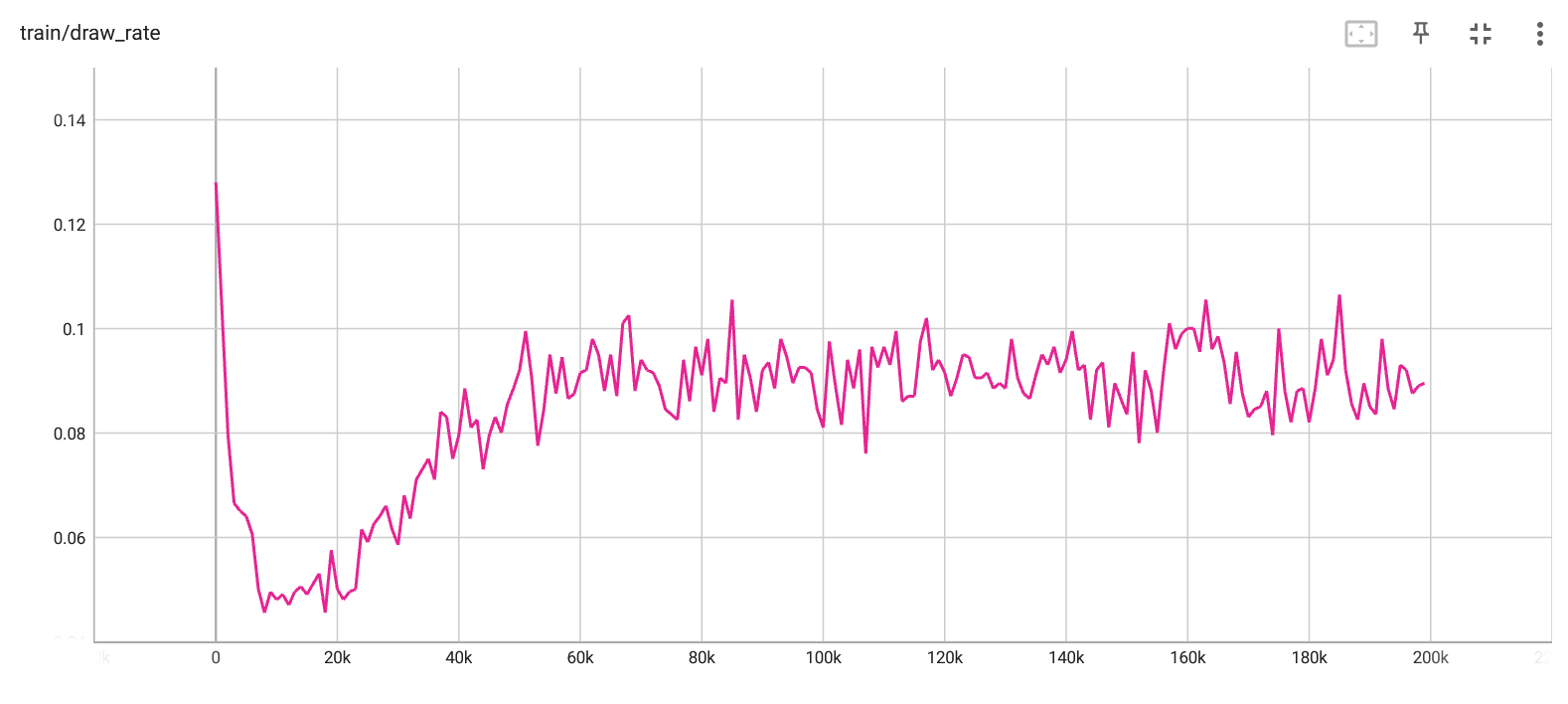
Draw rate per iteration. |
In the above images from tensorboard, we can see how the loss and draw rates against a random player improve as the agent learns via self-play. It seems that the training effectively converges at around 100,000 iterations, but I let it play for 200,000. By the end of training, the loss rate for the trained agent is around 1.5%, and the draw rate is around 8.5%, which leaves a win rate of about 90%. After seeing this, I felt that the trained agent should be able to win against a random agent near 100% of the time, and I was a bit surprised to see that it has such a high draw rate. I experimented with many different combinations of learning rates, the number of epochs, and a couple different types of training. In the end, I'm still not sure why the draw rate is so high. I think that I would need to investigate exactly in which scenarios it reaches a draw to understand this.
"Expert" Training
After reading about imitation learning (which this is not, I was just inspired), I was curious if training the Q-agent by playing against an expert (in this case a previously trained version of the agent) would help it to learn how to play faster, or improve its performance. To train against a previously trained 'expert' agent, the learning script can be run as:
python tictactoeqlearn.py --file qtable.pkl --expert qtable_trained.pkl
Where qtable_trained.pkl is a previously trained 'expert' Q-table.
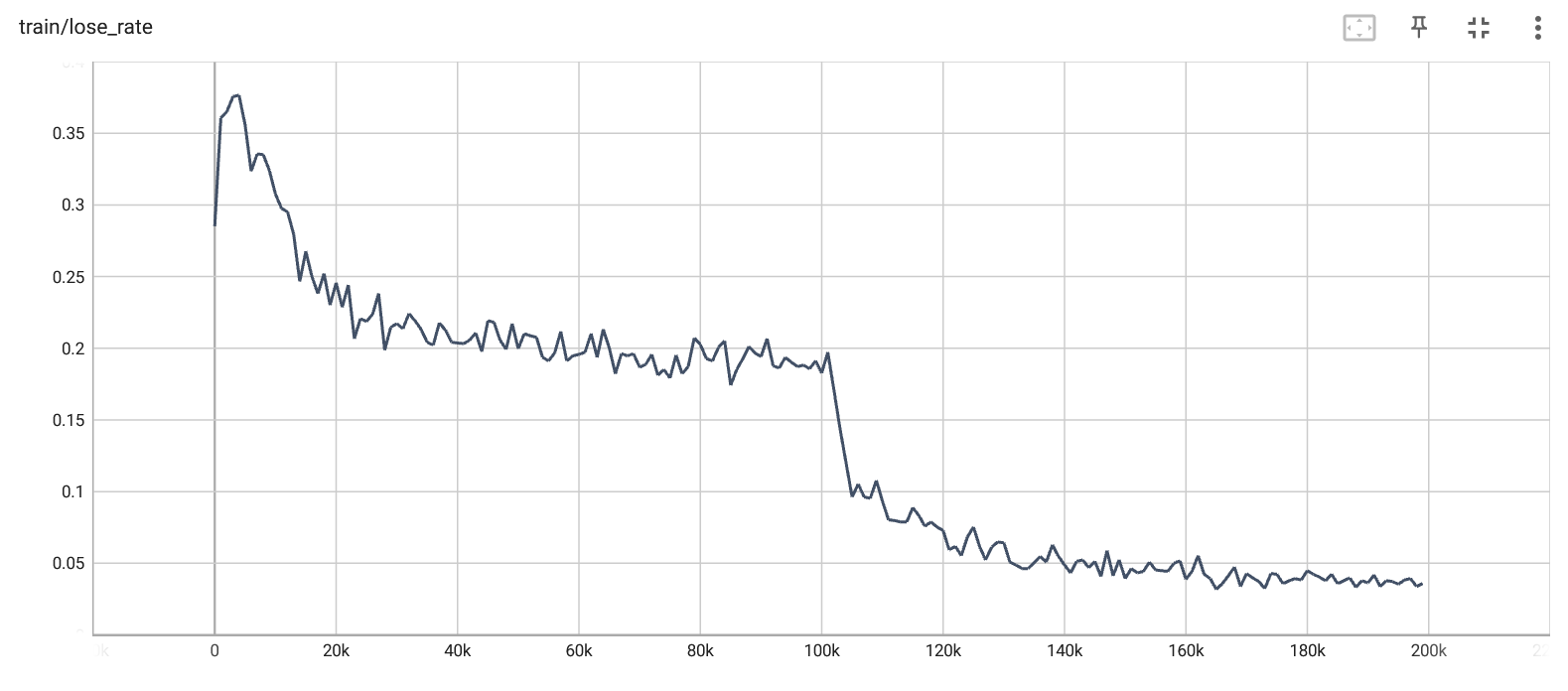
Loss rate per iteration. |
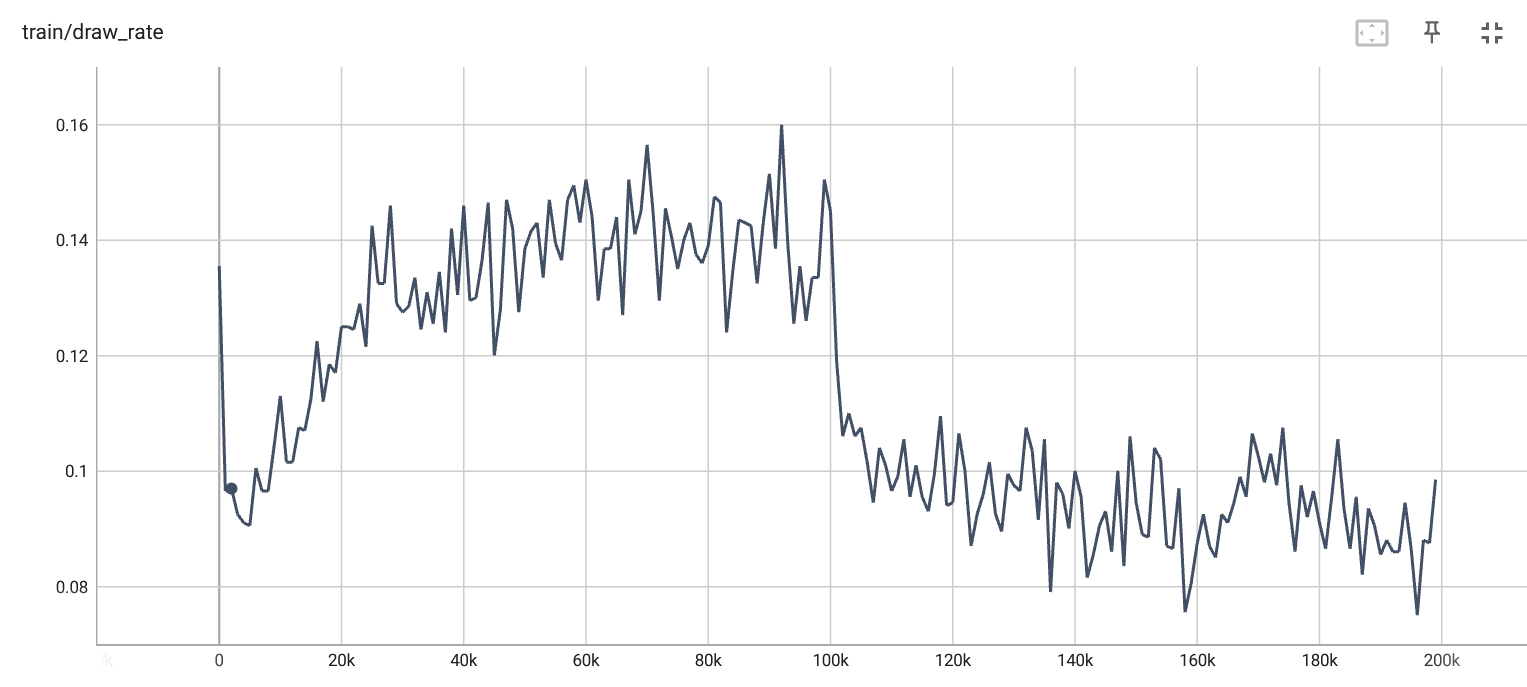
Draw rate per iteration. |
For the first 100k epochs, the fledgling Q-agent is trained by playing against the pre-trained expert. After 100k epochs, it is switch to playing against itself. This result is really not what I was expecting, and it's a fairly interesting training curve. Note that this represents its loss/draw rate against a random agent, not against the expert. Overall, I wasn't expecting it to plateau at such a high loss rate, since in the previous experiment using self-play it effectively reached 1% loss within the same 100k epochs. I left the training hyperparameters otherwise the same.
My (unverified) theories for why this happened:
- If the agent is losing each game to the expert rather quickly, then it isn't effectively exploring and learning from the entire state space.
- If the expert agent is playing too deterministically, then it's the same problem as #1.
- Self-play is more effective because it's training from the perspective of both players at the same time.
- Some combination of all of the above.
I would like to explore more about why this is happening, or maybe someone else already knows the solution. Unfortunately, I don't currently have time to go in-depth on this dilemma. I think what would be interesting to know is if this happens when playing against a human opponent as well (or some autonomous agent that otherwise plays perfectly). My overall guess is that it is due to the fact that the trained agent restricts exploration of the overall search space, which is really important for Q-learning.
Final Evaluation
By running python tictactoeqtest.py matrix_best.pkl --expert matrix_best.pkl we can run a series of tests on the trained Q-agent to see how it performs. This is what I got:
Playing Q-agent as X
Q-agent - Wins: 4480/5000 (0.896), Draws: 442/5000 (0.0884)
Playing Q-agent as O
Q-agent - Wins: 4102/5000 (0.8204), Draws: 635/5000 (0.127)
Playing random against random
Q-agent - Wins: 2948/5000 (0.5896), Draws: 638/5000 (0.1276)
Playing Q-agent as X against expert
Q-agent 1 - Wins: 1883/5000 (0.3766), Draws: 2491/5000 (0.4982)
Playing Q-agent as O against expert
Q-agent 1 - Wins: 674/5000 (0.1348), Draws: 2462/5000 (0.4924)
As expected, against a random opponent it wins or draws a game ~99% of the time when playing as X (first player) and ~95% of the time when playing O (second player). Playing against an 'expert' (in this case, itself) it wins or draws ~87% as X, and ~63% as O.
Test Play
You can try playing a game against the pre-trained agent by running:
python tictactoqplay.py matrix_best.pkl
or by running the next cell. It plays pretty well and will draw most games, though sometimes it's still possible to win.
from tictactoeqplay import play
play("matrix_best.pkl", export_plot = False)
| |
- | - | -
_____|_____|_____
| |
- | - | -
_____|_____|_____
| |
X | - | -
| |
| |
- | - | -
_____|_____|_____
| |
- | O | -
_____|_____|_____
| |
X | - | -
| |
| |
X | - | -
_____|_____|_____
| |
- | O | -
_____|_____|_____
| |
X | - | -
| |
| |
X | - | -
_____|_____|_____
| |
O | O | -
_____|_____|_____
| |
X | - | -
| |
| |
X | - | -
_____|_____|_____
| |
O | O | X
_____|_____|_____
| |
X | - | -
| |
| |
X | O | -
_____|_____|_____
| |
O | O | X
_____|_____|_____
| |
X | - | -
| |
| |
X | O | -
_____|_____|_____
| |
O | O | X
_____|_____|_____
| |
X | X | -
| |
| |
X | O | -
_____|_____|_____
| |
O | O | X
_____|_____|_____
| |
X | X | O
| |
| |
X | O | X
_____|_____|_____
| |
O | O | X
_____|_____|_____
| |
X | X | O
| |
Draw!
Visualisation
After I had already began my foray into Q-learning with tic-tac-toe, I found a really interesting series of blog posts by Paul Hiemstra on the same topic. While I think his code is overall better-looking than mine, I was most interested in the way he constructed a brilliant visualisation of the Q-table for different board states. I have little understanding for how it works, but I was at least able to adapt it to work with my own code. Here's a visualisation of some randomly selected board states, and their corresponding action values.

In the visualisation, blue squares are highly positively valued (high expectation of a positive reward), and red squares are highly negatively valued (high expectation of a negative reward). In any case, the Q-agent (always playing X in this case) will always select the square with the highest value when it isn't playing randomly. Looking at the table, most of the values seem intuitive to me, even if some of the board layouts are somewhat unlikely to occur in a real game. But, in general, the agent prefers the winning move.
Multi-Agent Policy-Based Methods for Tic-tac-toe
Library Horrors
Fair disclosure, this section doesn't have anything interesting in it. About 10 work-hours ago, I thought that I could use some online examples for RLlib (one of a few main RL libraries that looked usable) and then adapt them with a few small changes to work with tic-tac-toe so I could compare my Q-learning algorithm to a more modern algorithm such as PPO. I was really wrong.
Here is my Colab notebook that contains my attempts at getting this working. It's a mess. I started by trying to adapt this example from the Pistonball environment to work with the tic-tac-toe environment from PettingZoo. But that just elicited errors that I, as hard as I tried, could not solve. So I pivoted and did some more research, which led me to find this really detailed blog post by Clément Brutti-Mairesse. When I found that, I was thinking that all my problems would be solved, as his results are really good. However, he does not provide his full source, and so I still was not able to get past some specific errors that kept coming up again and again. Finally, in desperation, I threw out my goal of adapting an example, and I tried to simply run one of the provided basic examples. But even using this, there were more errors.
At that point, I finally gave up. I decided that I would open an issue in the library to fix it, but after some digging it looks like it's something that they're already working on here. I did, however, find out-of-date information in the docs for the PettingZoo library, and I opened an issue to fix that. But all the bugs, or errors, that I found really made it impossible to make any progress on this. The problem seems to be that the library API's (between PettingZoo, Gymnasium, and RLlib) are just out-of-sync, which makes it difficult to use them together even with the pre-made examples.
Back to the Basics
After cooling off for a few days, I wanted to try one more time to get a policy-based method to work. I found a simple example using PyTorch for single-agent RL.
I adapted my Q-learning code as best as I could to merge it with the policy model code from the example. What I found that was during training, I simply could not get the model to improve. In fact, the model was simply learning to lose with a high success rate (after a few thousand iterations, it could successfully throw the game ~99% of the time). I tried changing the model parameters, adding randomisation, and many other different ideas. Again, and again, the policy it learned just lost the game as fast as possible.
I'm still not sure what was happening, but I found what was able to get it to train to at least a more reasonable performance level was by making it impossible for the model to make illegal moves. In the tic-tac-toe environment, illegal moves are 'masked' by using the 'action_mask' from the observation object. With the Q-learning method, I was simply able to ignore this mask and allow the Q-table to learn that illegal moves carry negative rewards (making an illegal move immediately exits the game and yields a score of -1 to the player). For the policy network, however, that didn't work. So instead, I've written it so that if the model makes an illegal move, then a random valid move is returned instead.
Policy Results
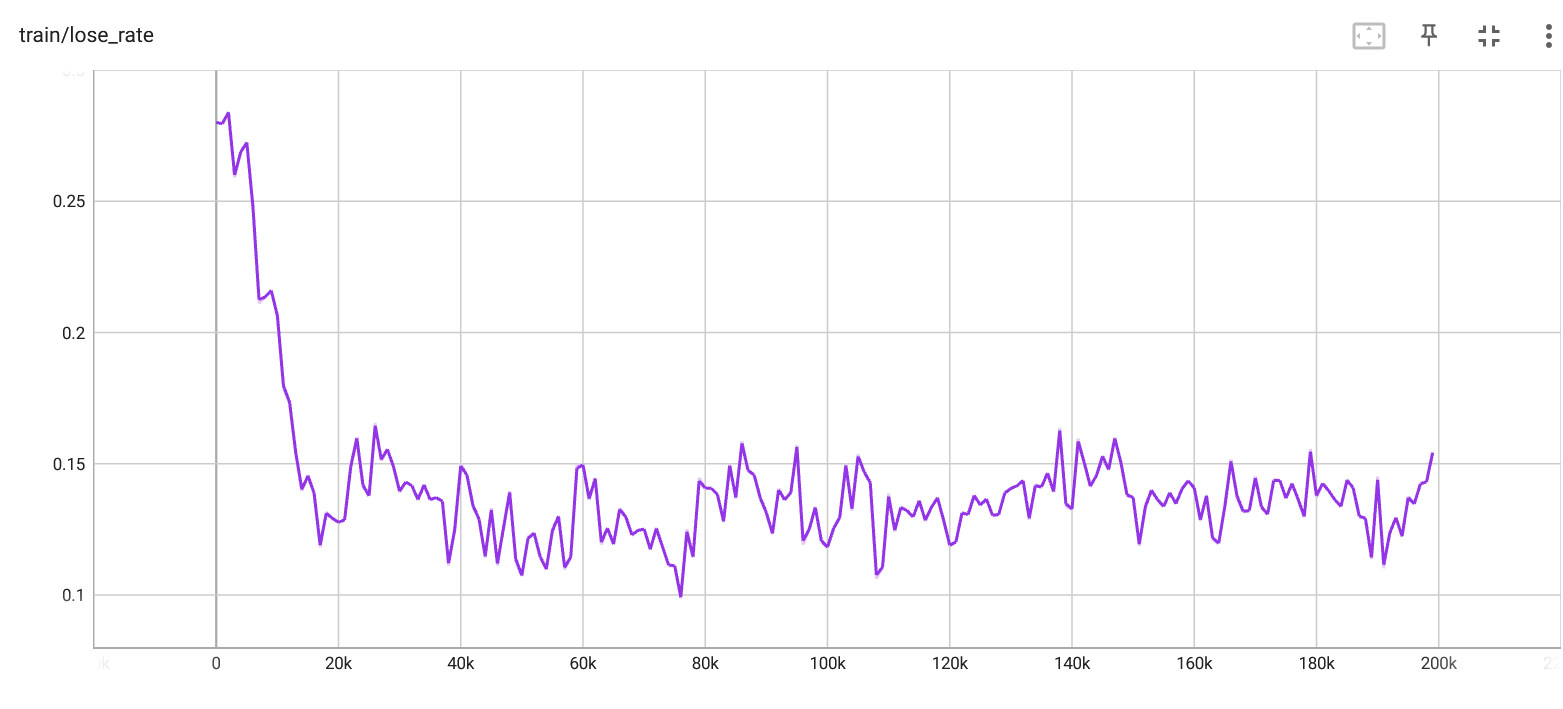
Loss rate per iteration. |
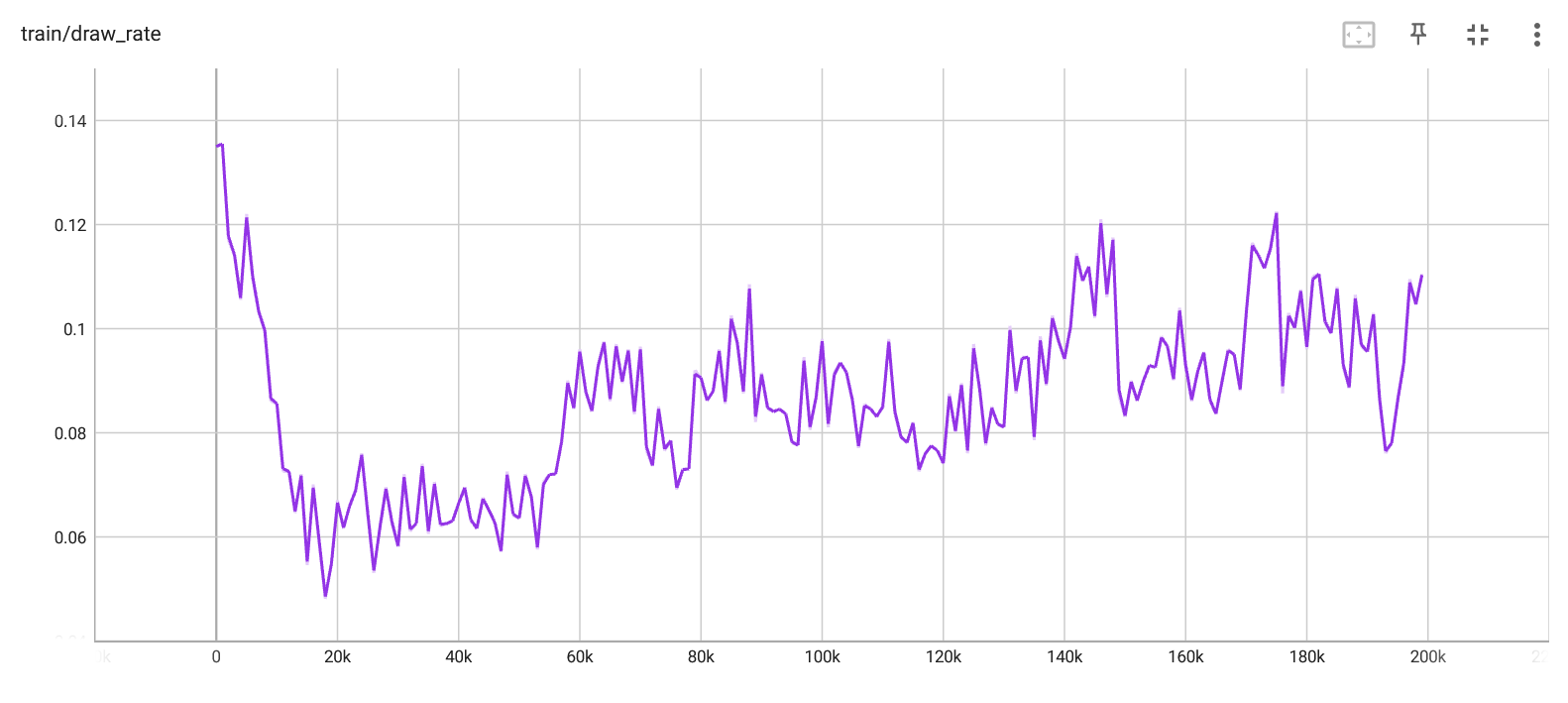
Draw rate per iteration. |
Looking at the diagram, it's clear that the performance is improving over time. These curves appear fairly similar to those for Q-learning, although we can see that it can't seem to get the loss rate as low as the Q-learning algorithm did. I'm not sure why this is, and it would probably take a fair bit more investigation and tuning to improve the performance.
Evaluation
For comparison against the Q-learning results, here is the output of my test script for the policy network. Run with python tictactoepolicytest.py --expert matrix_best.pkl saved_models/trained_policy.pth:
Playing Q-agent as X
Q-agent - Wins: 3204/5000 (0.6408), Draws: 905/5000 (0.181)
Playing Q-agent as O
Q-agent - Wins: 1003/5000 (0.2006), Draws: 1706/5000 (0.3412)
Playing random against random
Q-agent - Wins: 2946/5000 (0.5892), Draws: 655/5000 (0.131)
Playing Q-agent as X against expert
Q-agent 1 - Wins: 212/5000 (0.0424), Draws: 1435/5000 (0.287)
Playing Q-agent as O against expert
Q-agent 1 - Wins: 72/5000 (0.0144), Draws: 1282/5000 (0.2564)
In this case, the 'expert' is the trained Q-agent from before. We can see that it's at least better than a random player, but it still loses the majority of the time to our model from Q-learning.
Comparison
I was curious how the Q-table visualisation would compare against the policy estimation from the trained policy network. It's not a 1:1 comparison, since the policy network is generating probabilities of taking a specific action. But the visualisation is still interesting, and I'm happy to see that there is at least some similarity between the two, considering how much worse my policy agent performed after training.
You can see the plot comparison below, created with python tictactoepolicyplot.py saved_models/trained_policy.pth matrix_best.pkl:
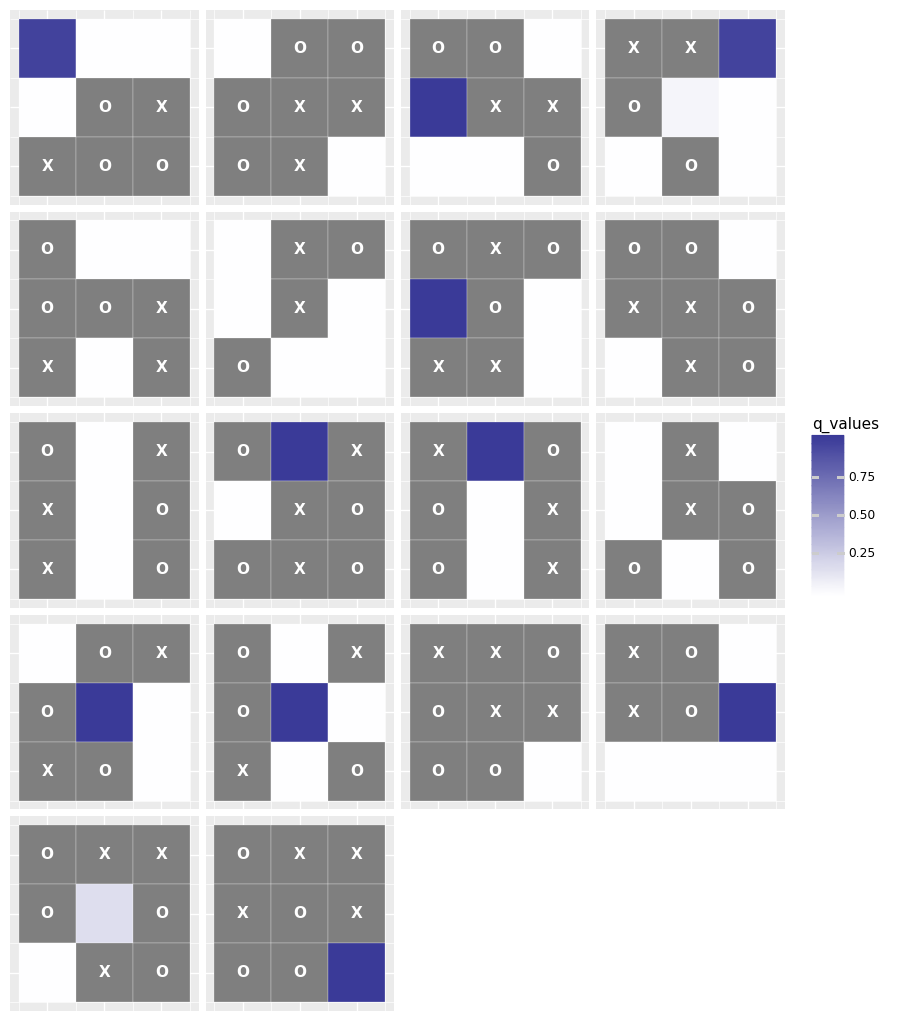
Policy probabilities from policy model |
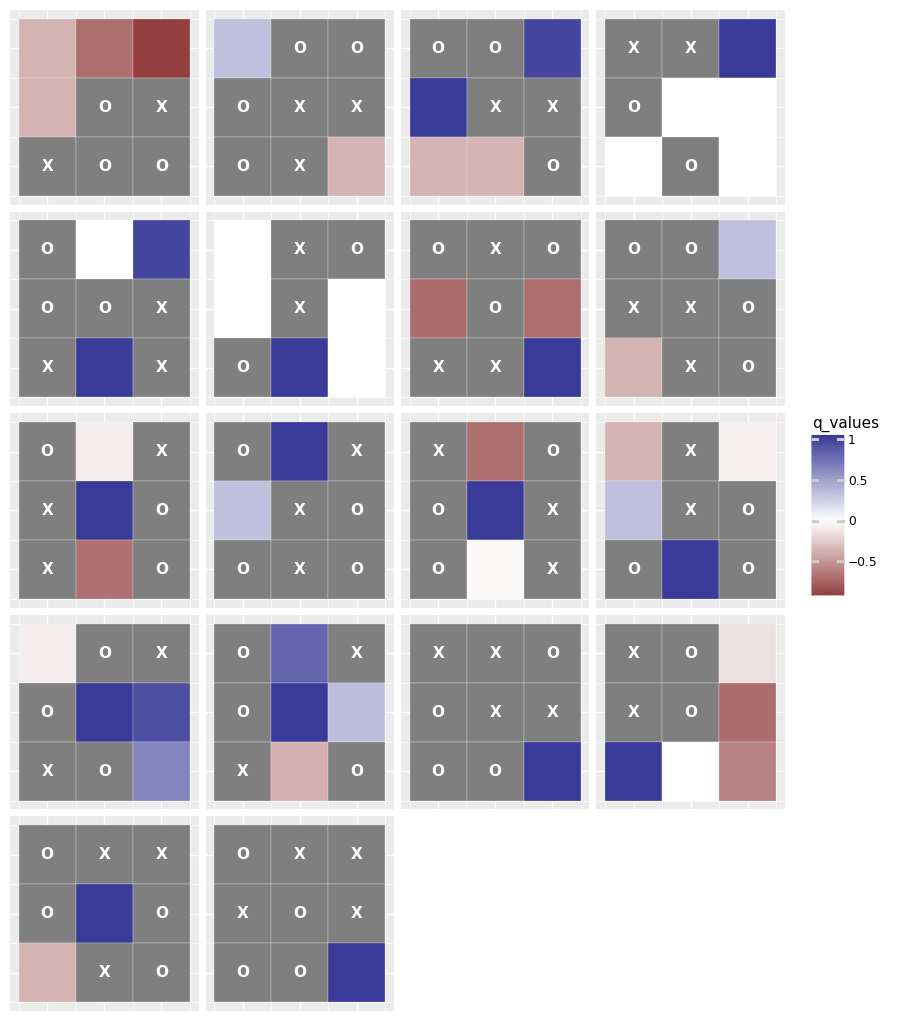
Q-table values from Q model. |
Conclusion
In this project I have engaged with some concepts of game theory from the approach of multi-agent reinforcement learning. I really wanted to create a more impressive project, but among the many issues I faced in getting these examples to work, I was also distracted by projects that I have been working on for other parallel courses. I can at least appreciate that I learned a lot through the literature review that I performed before I started coding my examples. Reinforcement learning is an extremely interesting area of 'AI', where game theory and other research areas overlap. As a subset, I think that MARL is more interesting since it seems more realistic. If we are, in some sense, modelling our agents on humans, we need to consider that learning doesn't occur in a vacuum. I think that self-play is an interesting subset of this area, because it allows agent training without much supervision. However, it definitely still has 'open problems' as mentioned by Giovanni and Zell.
Future Work
If I were to continue working in this area, it would be really nice to get RLlib working. However, its relationship with PettingZoo seems currently unstable, and makes practical projects difficult. Besides RLlib, I found that PyTorch has in the last year released a new RL library (torchRL) that's worth checking. I think I would get away from tic-tac-toe and see what I could do with some more complex and interesting games. But, who knew that it would be this difficult even with a game as simple as tic-tac-toe?
References
[1] M. Galarnyk, “An Introduction to Reinforcement Learning with OpenAI Gym, RLlib, and Google Colab,” Medium, Sep. 29, 2021. https://towardsdatascience.com/an-introduction-to-reinforcement-learning-with-openai-gym-rllib-and-google-colab-48fc1ddfb889 (accessed Mar. 16, 2023).
[2] Y. Yang and J. Wang, “An Overview of Multi-Agent Reinforcement Learning from Game Theoretical Perspective.” arXiv, Mar. 17, 2021. doi: 10.48550/arXiv.2011.00583.
[3] A. Mika, “Creating a Tic-Tac-Toe game with a Q-learning AI which masters the game,” Medium, Dec. 28, 2020. https://towardsdatascience.com/creating-a-tic-tac-toe-game-with-a-q-learning-ai-which-masters-the-game-9b0567d24de (accessed Mar. 13, 2023).
[4] “Deep RL Bootcamp Lecture 4A: Policy Gradients - YouTube.” https://www.youtube.com/watch?v=S_gwYj1Q-44&list=PLFihX_3MLxS8VY0y851LZ6TAZWUZeQ0yN&index=5 (accessed Mar. 12, 2023).
[5] D. Zha et al., “DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning.” arXiv, Jun. 10, 2021. doi: 10.48550/arXiv.2106.06135.
[6] D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi, “Dream to Control: Learning Behaviors by Latent Imagination.” arXiv, Mar. 17, 2020. doi: 10.48550/arXiv.1912.01603.
[7] “gym_example.” derwen.ai, Jan. 15, 2023. Accessed: Mar. 16, 2023. [Online]. Available: https://github.com/DerwenAI/gym_example/blob/d6f97de9f751bb2ae04e724ec5d223cbb5ed2290/train.py
[8] “Gymnasium Documentation.” https://gymnasium.farama.org/tutorials/training_agents/blackjack_tutorial/ (accessed Mar. 13, 2023).
[9] K. Ciosek, “Imitation Learning by Reinforcement Learning.” arXiv, Mar. 15, 2022. doi: 10.48550/arXiv.2108.04763.
[10] “Imitation Learning by Reinforcement Learning,” DeepAI, Aug. 10, 2021. https://deepai.org/publication/imitation-learning-by-reinforcement-learning (accessed Mar. 12, 2023).
[11] D. Garg, “Inverse Q-Learning (IQ-Learn).” Mar. 07, 2023. Accessed: Mar. 12, 2023. [Online]. Available: https://github.com/Div99/IQ-Learn
[12] M. F. Dixon, I. Halperin, and P. Bilokon, “Inverse Reinforcement Learning and Imitation Learning,” in Machine Learning in Finance: From Theory to Practice, M. F. Dixon, I. Halperin, and P. Bilokon, Eds., Cham: Springer International Publishing, 2020, pp. 419–517. doi: 10.1007/978-3-030-41068-1_11.
[13] D. Garg, S. Chakraborty, C. Cundy, J. Song, M. Geist, and S. Ermon, “IQ-Learn: Inverse soft-Q Learning for Imitation.” arXiv, Nov. 03, 2022. doi: 10.48550/arXiv.2106.12142.
[14] T. D. Ahle, “Lair’s Dice by self-play.” Mar. 09, 2023. Accessed: Mar. 13, 2023. [Online]. Available: https://github.com/thomasahle/liars-dice
[15] T. D. Ahle, “Liar’s Dice by Self-Play,” Medium, Jan. 16, 2022. https://towardsdatascience.com/lairs-dice-by-self-play-3bbed6addde0 (accessed Mar. 13, 2023).
[16] J. Schrittwieser et al., “Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model,” Nature, vol. 588, no. 7839, pp. 604–609, Dec. 2020, doi: 10.1038/s41586-020-03051-4.
[17] “Multi-agent reinforcement learning — Introduction to Reinforcement Learning.” https://gibberblot.github.io/rl-notes/multi-agent/multi-agent-rl.html (accessed Apr. 05, 2023).
[18] P. Hiemstra, “PaulHiemstra/qlearning_paper.” Aug. 29, 2021. Accessed: Mar. 16, 2023. [Online]. Available: https://github.com/PaulHiemstra/qlearning_paper/blob/069b31063f675f48cc493ec176da4dc1715d701c/support_functions.py
[19] “PettingZoo Documentation.” https://pettingzoo.farama.org/environments/classic/tictactoe/ (accessed Mar. 16, 2023).
[20] M. Schmid et al., “Player of Games.” arXiv, Dec. 06, 2021. doi: 10.48550/arXiv.2112.03178.
[21] “PyTorch Examples.” pytorch, Apr. 08, 2023. Accessed: Apr. 08, 2023. [Online]. Available: https://github.com/pytorch/examples/blob/54f4572509891883a947411fd7239237dd2a39c3/reinforcement_learning/reinforce.py
[22] “ray-project/ray.” ray-project, Apr. 08, 2023. Accessed: Apr. 08, 2023. [Online]. Available: https://github.com/ray-project/ray/blob/4f913fbabedf0a05ff5e5784328c7aaf781295b7/rllib/examples/rock_paper_scissors_multiagent.py
[23] “Replicable-MARL/MARLlib: The MARL extension for RLlib. A benchmark for research and industry.” https://github.com/Replicable-MARL/MARLlib (accessed Mar. 12, 2023).
[24] “Rl Series Paul – Towards Data Science.” https://towardsdatascience.com/tagged/rl-series-paul (accessed Apr. 05, 2023).
[25] “RLCard: A Toolkit for Reinforcement Learning in Card Games — RLcard 0.0.1 documentation.” https://rlcard.org/ (accessed Mar. 12, 2023).
[26] “RLlib: Industry-Grade Reinforcement Learning — Ray 2.3.0.” https://docs.ray.io/en/latest/rllib/index.html (accessed Mar. 12, 2023).
[27] “[RLlib] Remove return_info from reset() in pettingzoo_env.py. by elliottower · Pull Request #33470 · ray-project/ray.” https://github.com/ray-project/ray/pull/33470 (accessed Apr. 08, 2023).
[28] E. Steinberger, “Single Deep Counterfactual Regret Minimization,” Dec. 2019, Accessed: Mar. 13, 2023. [Online]. Available: https://openreview.net/forum?id=ByebT3EYvr
[29] A. DiGiovanni and E. C. Zell, “Survey of Self-Play in Reinforcement Learning.” arXiv, Jul. 06, 2021. doi: 10.48550/arXiv.2107.02850.
[30] R. Sutton and A. Bart, Sutton & Barto Book: Reinforcement Learning: An Introduction, 2nd Edition. MIT Press, 2018. Accessed: Apr. 03, 2023. [Online]. Available: http://incompleteideas.net/book/the-book-2nd.html
[31] “The Minimax Algorithm in Tic-Tac-Toe: When graphs, game theory and algorithms come together : Networks Course blog for INFO 2040/CS 2850/Econ 2040/SOC 2090.” https://blogs.cornell.edu/info2040/2022/09/13/56590/ (accessed Apr. 05, 2023).
[32] C. Yu et al., “The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games.” arXiv, Nov. 04, 2022. doi: 10.48550/arXiv.2103.01955.
Study Playlist
Did you know that you can embed HTML iframe widgets into markdown content? I didn't. Spotify isn't paying me to put this here, nor is this an endorsement. I just like listening to this playlist while I'm working on projects, and it helps keep my anxiety and existential dread to a minimum.